
- Spark 데이터 처리
- Spark 데이터 구조: RDD, DataFrame, Dataset
- 프로그램 구조
Spark 데이터 처리
Hive, Presto 보다 더 많은 기능을 제공하기 위해 Spark 사용
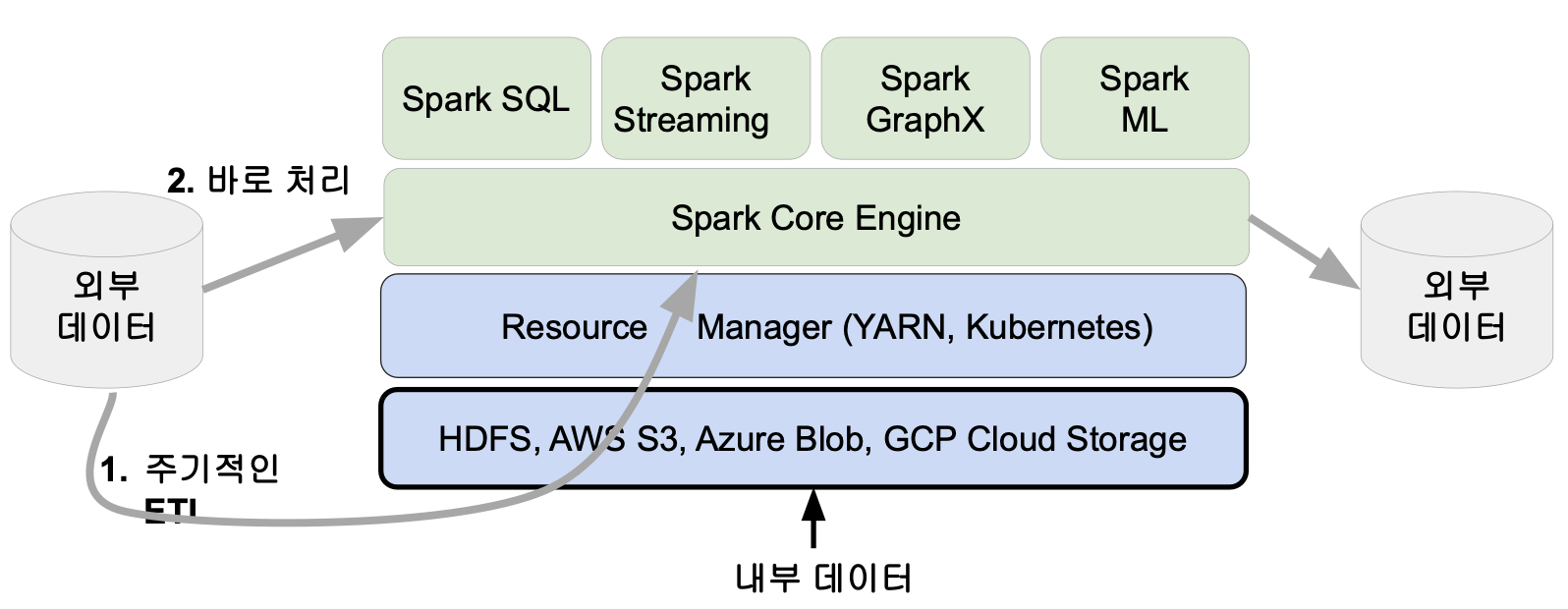
- 외부 데이터(RDB, NoSQL)로부터 주기적인 ETL을 해서 가지고 온다. (Airflow 등..)
- Spark에서 바로 처리하는 방법도 존재한다. (Spark Streaming)
데이터 병렬처리가 가능하려면?
데이터가 먼저 분산되어야함: (자신만의) 파일시스템이 따로 존재하지 않아서, 분산환경 시스템을 가져야함
- 하둡 맵의 데이터 처리 단위는 디스크에 있는 데이터 블록 (128MB)
- (128MB가 너무 크거나 작으면) hdfs-site.xml에 있는 dfs.block.size 프로퍼티로 결정한다.
- Spark에서는 이를 파티션 (Partition)이라 부름. 파티션의 기본크기도 128MB (환경변수로 조정가능함)
- spark.sql.files.maxPartitionBytes: HDFS등에 있는 파일을 읽어올 때만 적용됨
- 다음으로 나눠진 데이터를 각각 따로 동시 처리
- 맵리듀스에서 N개의 데이터 블록으로 구성된 파일 처리시 N개의 Map 태스크가 실행(블럭 하나당 한개의 map 태스크)
- Spark에서는 파티션 단위로 메모리로 로드되어 Executor가 배정됨 (이론적으로는 한 Executor에서 여러 파티션 처리 가능)
처리 데이터를 나누기 -> 파티션 -> 병렬처리

- 데이터 소스(HDFS가 아닌 Postgres, MySQL등...)에 따라서 JDBC에 의해 파티셔닝이 서로 달라진다.
- 따로 JDBC 설정을 해주지 않는다면 하나의 파티션으로 만들어낸다.
- 파티셔닝은 RDD 또는 DataSet으로 존재한다.
- Executor의 수 X Executor당 CPU의 수 가 이상적인 파티션이다.
- 여기서는 Executor당 cpu 코어가 1개라고 가정할때, 최고로 실행가능한 task는 2개까지이다.
- P1, P2 실행 후 -> P3, P4 배정됨
- 동시에 실행되는건 Spark Cluster의 Capacity를 의미한다.
Spark 데이터 처리 흐름
- 데이터프레임은 작은 파티션들로 구성됨 (Pandas의 DF와 비슷하지만, 처리하는 크기가 더 크고 DF가 수정 불가능함)
- 데이터프레임은 한번 만들어지면 수정 불가 (Immutable)
- 입력 데이터프레임을 원하는 결과 도출까지 다른 데이터 프레임으로 계속 변환
- (sort, group by : 데이터 이동이 되고 전송을 통해 새로운 파티셔닝이 이뤄짐), (filter, map : 다른 서버로 이동할 일 없음), join, ...

셔플링
파티션간에 데이터 이동이 필요한 경우 발생
- 셔플링이 발생하는 경우는?
- 명시적 파티션을 새롭게 하는 경우 (Coalesce 사용해서 파티션 수를 줄이기)
- 시스템에 의해 이뤄지는 셔플링 (그룹핑(group by) 등의 aggregation이나 sorting)
- 셔플링이 발생할 때 네트웍을 타고 데이터가 이동하게 됨
- 몇 개의 파티션이 결과로 만들어질까? : spark.sql.shuffle.partitions이 결정
- 기본값은 200이며 이는 최대 파티션 수
- 오퍼레이션에 따라 파티션 수가 결정됨 : random, hashing partition : group by, range partition : sorting 등등
- sorting의 경우 range partition을 사용함, 적당히 샘플링을 함으로서 파티셔닝을 가능하게끔 한다.
- 또한 이때 Data Skew 발생 가능!
- 몇 개의 파티션이 결과로 만들어질까? : spark.sql.shuffle.partitions이 결정


- Hashing partitioning 할 때는 같은 값을 가지는 키 Field에 따라 만들어지는 파티셔닝으로 나뉘어진다.
- Range partitioning 할 때는 범위를 가지는 키 Field에 따라 파티션된다.
Spark 데이터 구조: RDD, DataFrame, Dataset
- Spark 데이터 구조 : RDD, DataFrame, Dataset (Immutable Distributed Data)
- 2016년에 DataFrame과 Dataset은 하나의 API로 통합됨
- 모두 파티션으로 나뉘어 Spark에서 처리됨
|
RDD
|
DataFrame
|
Dataset
|
|
|
무엇인지?
|
Distributed collection of records (structured & unstructured)
|
RDD organized into named column
|
Extension of data frame
|
|
언제 소개되었는지
|
1.0
|
1.3
|
1.6
|
|
컴파일타임 타입 체크
|
No
|
No
|
Yes
|
|
사용하기 쉬운 API
|
No
|
Yes
|
Yes
|
|
SparkSQL 기반
|
No
|
Yes
|
Yes
|
|
Catalyst Optimizer
|
No
|
Yes
|
Yes
|
- RDD (Resilient Distributed Dataset)
- 로우레벨 데이터로 클러스터내의 서버에 분산된 데이터를 지칭
- 레코드별로 존재하지만 스키마가 존재하지 않음
- 구조화된 데이터나 비구조화된 데이터 모두 지원
- DataFrame과 Dataset (지금은 동일한 것이라고 봐도 무방함, SparkSQL 엔진 위에서 돌아감)
- RDD위에 만들어지는 RDD와는 달리 필드 정보를 갖고 있음 (테이블)
- Dataset은 타입 정보가 존재하며 컴파일 언어에서 사용가능
- 컴파일 언어: Scala/Java에서 사용가능
- PySpark에서는 DataFrame을 사용
- 실제 쿼리를 Physical 한 RDD operation으로 변경할 때, 가장 경제적인 Execution Plan으로 실행된다.
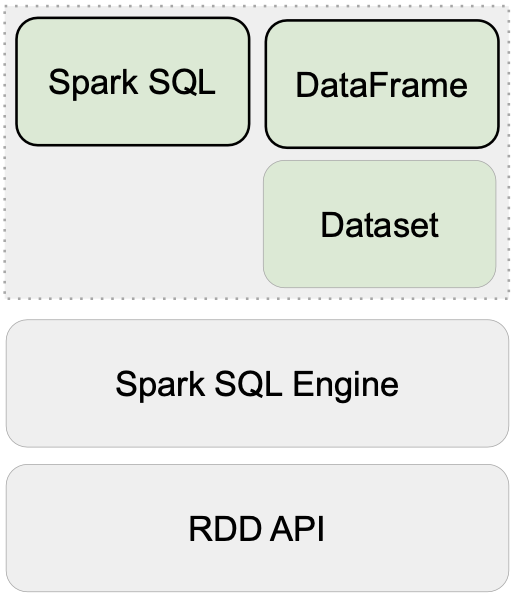
Spark SQL Engine 에서 하는 4가지 일
- Code Analysis : 컬럼, 테이블 지정(typo 및 type 오류를 여기서 걸러냄)
- Logical Optimization (Catalyst Optimizer) : 여러 방안을 만들어내고 catalyst가 Standard SQL방식으로 선택
- Physical Planning : 비용이 가장 싼것을 골라서 RDD Operation Code를 작성한다.
- Code Generation (Project Tungsten) : RDD OpCdoe 에서 Java byte Code로 변경한다.
Spark 데이터 구조 - RDD
- 변경이 불가능한 분산 저장된 데이터 (= DataSet, DataFrame도 RDD에 종속되기 때문에 변경 불가함)
- RDD는 다수의 파티션으로 구성
- 로우레벨의 함수형 변환 지원 (map, filter, flatMap 등등)
- 일반 파이썬 데이터는 parallelize 함수로 RDD로 변환 (리스트를 RDD로)
- 반대는 collect로 파이썬 데이터로 변환가능

(rdd가 엄청 크다고 할 때 collect하게 된다면.. 에러가 나게 됨(그럴 필요도 없을뿐더러))
Spark 데이터 구조 - DataFrame
- 변경이 불가한 분산 저장된 데이터
- RDD와는 다르게 관계형 데이터베이스 테이블처럼 컬럼 나눠 저장
- 판다스의 데이터 프레임 혹은 관계형 데이터베이스의 테이블과 거의 흡사 (판다스를 많이 보고 Spark를 만듦)
- 다양한 데이터소스 지원: HDFS, Hive, 외부 데이터베이스, RDD 등등
- 스칼라, 자바, 파이썬과 같은 언어에서 지원
프로그램 구조
Spark Session 생성
- Spark 프로그램의 시작은 SparkSession을 만드는 것
- 프로그램마다 하나를 만들어 Spark Cluster와 통신: Singleton 객체
- Spark 2.0에서 처음 소개됨
- Spark Session을 통해 Spark이 제공해주는 다양한 기능을 사용
- DataFrame, SQL, Streaming, ML API 모두 이 객체로 통신
- config 메소드를 이용해 다양한 환경설정 가능 (빌더 디자인 패턴을 통해 단계별로도 가능)
- 단, RDD와 관련된 작업을 할때는 SparkSession 밑의 sparkContext 객체를 사용
Spark 세션 생성 - PySpark 예제

from pyspark.sql import SparkSession
# SparkSession은 싱글턴 #생성되어있다면 만들어진것을 리턴, 안생성되어있으면 만들어짐
spark = SparkSession.builder\ #빌더 디자인 패턴으로 생성
.master("local[*]")\ #로컬 스파크 클러스터 사용(스레드 지정)
.appName('PySpark Tutorial')\ #스파크 클러스터의 이름 지정 (.config를 통해 설정가능하다)
.getOrCreate()
...
spark.stop() # 모든 리소스 종료- Spark SQL Engine이 중심으로 동작함: 2.0으로 변경되면서 DF, DataSet등 모두 SparkSQL 엔진 위에서 돌아가는 걸로 변경됨
Spark Session 환경 변수
- Spark Session을 만들 때 다양한 환경 설정이 가능
- executor별 메모리: spark.executor.memory (기본값: 1GB)
- executor별 CPU수: spark.executor.cores (YARN에서는 기본값 1)
- driver 메모리: spark.driver.memory (기본값: 1GB)
- Shuffle후 Partition의 수: spark.sql.shuffle.partitions (기본값: (최대)200개 )
- 가능한 모든 환경변수 옵션은 여기에서 찾을 수 있음
- 사용하는 Resource Manager에 따라 환경변수가 많이 달라짐
- Spark Session 환경 설정 방법 4가지 (충돌시 우선순위는 아래일수록 높음: 내가 인자로 넘겨준게 더 높은 우선순위)
- 환경변수, $SPARK_HOME/conf/spark_defaults.conf (보통 Spark Cluster 어드민이 관리)
- spark-submit 명령의 커맨드라인 파라미터
- SparkSession 만들때 지정 (SparkConf 클래스를 사용해서 파라미터로 던져주기)
SparkSession 생성시 일일히 지정하는 경우
from pyspark.sql import SparkSession
# SparkSession은 싱글턴
spark = SparkSession.builder\
.master("local[*]")\
.appName('PySpark Tutorial')\
.config("spark.some.config.option1", "some-value") \
.config("spark.some.config.option2", "some-value") \
.getOrCreate()위에서 언급한 우선순위가 고려된 상태이고 그 위에 overriding이 되고 있다 이해하면 된다.
SparkConf 객체에 환경 설정하고 SparkSession에 지정
from pyspark.sql import SparkSession
from pyspark import SparkConf
conf = SparkConf()
conf.set("spark.app.name", "PySpark Tutorial")
conf.set("spark.master", "local[*]")
# SparkSession은 싱글턴
spark = SparkSession.builder\
.config(conf=conf) \
.getOrCreate()
- 전체적인 플로우
- Spark 세션(SparkSession)을 만들기
- 입력 데이터 로딩
- 데이터 조작 작업 (판다스와 아주 흡사) (DataFrame API나 Spark SQL을 사용)
- 원하는 결과가 나올때까지 새로운 DataFrame을 생성 : 최종결과 저장

Spark Session이 지원하는 데이터 소스
- spark.read(DataFrameReader)를 사용하여 데이터 프레임으로 로드
- DataFrame.write(DataFrameWriter)을 사용하여 데이터 프레임을 저장
- 많이 사용되는 데이터 소스들 : HDFS 파일
- CSV, JSON, Parquet, ORC, Text, Avro
- Hive 테이블
- JDBC 관계형 데이터베이스 ( 모두 Spark 세션에서 입출력 가능한다.)
- 클라우드 기반 데이터 시스템 (Redshift, BigQuery ..)
- 스트리밍 시스템 (Kafka, Kinesis..)
'Spark' 카테고리의 다른 글
| [Spark] Spark 내부동작과 클라우드 옵션(Part1. Spark 내부동작) (1) | 2024.02.13 |
|---|---|
| [Spark] Spark 프로그래밍: SQL (3) | 2024.02.13 |
| [Spark] Spark 프로그래밍: DataFrame (2) (0) | 2024.02.12 |
| [Spark] 빅데이터 처리와 Spark 소개(2) (1) | 2024.02.10 |
| [Spark] 빅데이터 처리와 Spark 소개(1) (1) | 2024.02.09 |



