
- 빅데이터 정의
- 빅데이터 처리가 갖는 특징
- 하둡의 등장과 소개
- Yarn
빅데이터 정의
- 서버 한대로 처리할 수 없는 규모의 데이터
- 기존의 소프트웨어로는 처리할 수 없는 규모의 데이터
- 기존의 데이터베이스는 분산환경을 염두에 두지 않고 Scale-up의 접근방식을 가져감
- Scale-out의 접근은 Scalable 하다고 이야기 할 수 있다.

- 웹 검색엔진 개발은 진정한 대용량 데이터 처리
- 요즘은 웹 자체가 NLP 거대모델 개발의 훈련 데이터로 사용되고 있음
-
구글이 빅데이터 기술의 발전에 지대한 공헌
빅데이터 처리가 갖는 특징
- 먼저 큰 데이터를 손실없이 보관할 방법이 필요: 스토리지
- 처리 시간이 오래 걸림: 병렬처리 (이런 데이터들은 비구조화된 데이터일 가능성이 높음: SQL만으로는 부족하다.)
결국 다수의 컴퓨터로 구성된 프레임웍이 필요하다!
- 다수의 서버로 되어있는 서버는 다음과 같은 특징을 가진다.
- 분산 환경 기반 : 1대 혹은 그 이상의 서버
- Fault Tolerance : 소수의 서버가 고장나도 동작해야함
- 확장이 용이해야함 : Scale out 가능해야함
- 이러한 컴퓨팅의 구성은 Master-Slave 의 구조로 분산환경이 이뤄지는 경우가 많다!


하둡의 등장과 소개

- 구글랩 발표 논문들에 기반해 만든 오픈소스 프로젝트
- 2003년 The Google File System
- 2004년 MapReduce: Simplified Data Processing on Large Cluster
하둡이란?
Hortonworks의 hadoop 정의:
An open source software platform for distributed storage(HDFS)
and distributed processing(MapReduce) of very large data sets on computer clusters built from commodity hardware
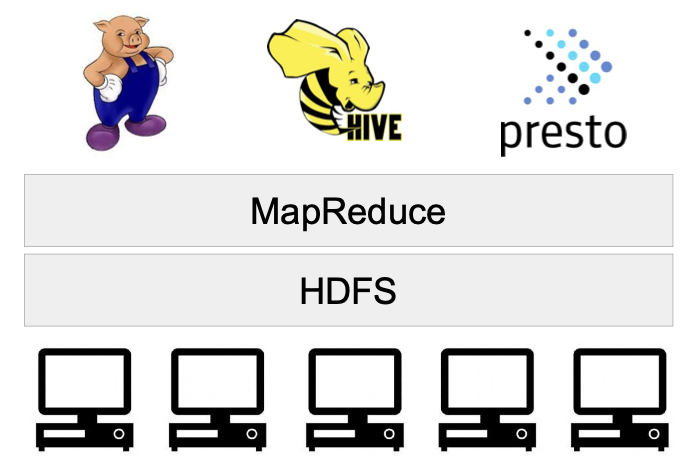
- 다수의 노드로 구성된 클러스터 시스템 (Cluster) : 마치 하나의 거대한 컴퓨터처럼 동작한다.
- 사실은 다수의 컴퓨터들이 복잡한 소프트웨어로 통제된다.
- 맵 리듀스는 두 개의 Operation을 지원한다. ('Map' 과 'Reduce')
- 그러나 두개 의 오퍼레이션밖에 지원하기 때문에 프로그래밍이 너무 어려워졌다. (생산성 감소)
- 따라서, MapReduce위에서 분산처리 시스템을 지원하는 방식으로 변경되기 시작함
- Hive, Presto는 SQL과 동일하다고 보면 되고, Pig는 deprecated됨..

- 하둡 2.0에서는 맵 리듀스보다 더 일반적인 컴퓨팅 프레임워크(Yarn)을 구성하여 그 위에 구성되었다.위의 hadoop1.0 에서의
- 이에따라, 위의 hadoop1.0 에서의 Presto, Hive, Pig는 Yarn위의 MR위에서 돌아간다.
- 하둡은 YARN이란 이름의 분산처리 시스템위에서 동작하는 애플리케이션이 됨
- Spark은 YARN위에서 애플리케이션 레이어로 실행됨
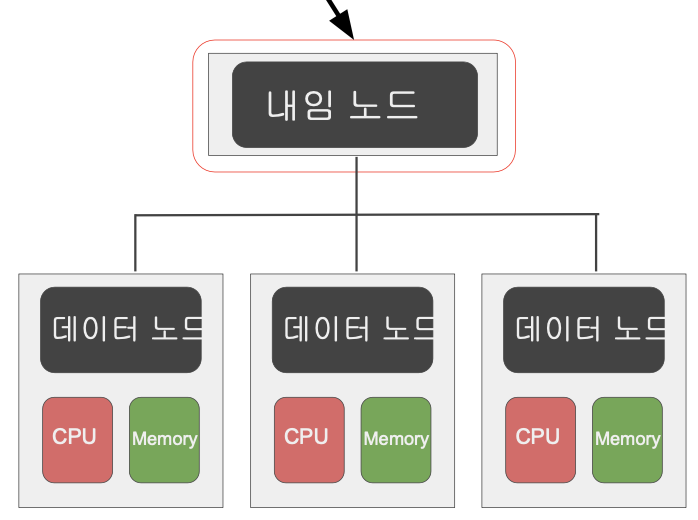
- HDFS - 분산 파일 시스템
- 데이터를 블록단위로 나눠 저장 : 디폴트 블록 크기는 128MB
- 블록 복제 방식 (Replication) : 각 블록은 3개 이상 중복 저장됨, Fault tolerance 보장한다.
- 하둡 2.0 네임노드 이중화 지원 : Master-Slave 구조에서 네임노드는 마스터 역할 예전에는 매뉴얼 작업으로 설정했는데 2.0에서는 네임노드를 이중화해서(Active, Standby)모드를 구성했다.
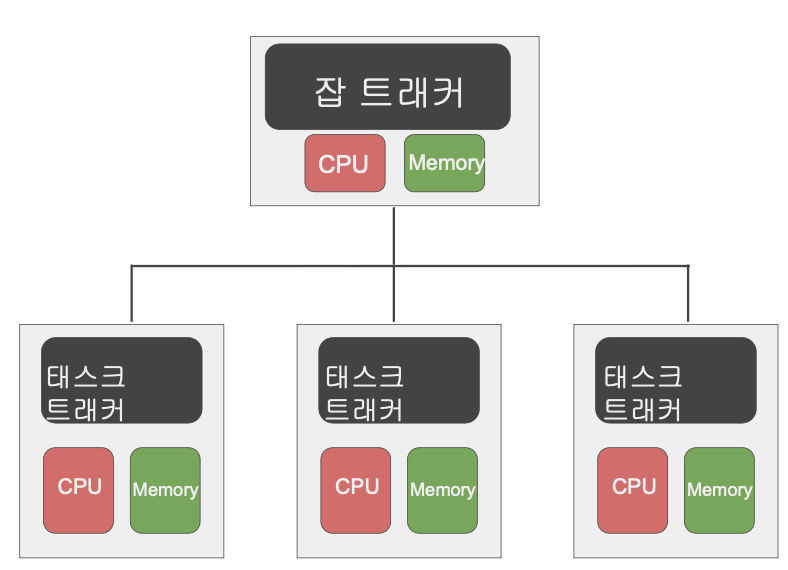
- MapReduce - 분산 컴퓨팅
- 하나의 잡 트래커(master)와 다수의 태스크 트래커(Slave)로 구성됨
- 잡 트래커가 일을 나눠서 다수의 태스크 트래커에게 분배, 태스크 트래커에서 병렬처리
- MapReduce만 지원함(제너럴한 시스템이 아님)
Yarn

-
세부 리소스 관리가 가능한 범용 컴퓨팅 프레임워크, 맵 리듀스의 구조와 크게 다르진 않다.
- 노드 매니저:
- 노드 매니저는 각 슬레이브마다 설치되어 있음, 한 노드 매니저에 다수의 컨테이너를 가질 수 있다.
- 컨테이너는 자바에서의 JVM이라고 보면된다. 두 종류가 있음 앱 마스터, 태스크
- 마스터의 요구에 따라서 할당/리포팅을 하게 해주게 된다.
- MapReduce, Spark등이 위에서 구현된다.
Yarn의 동작
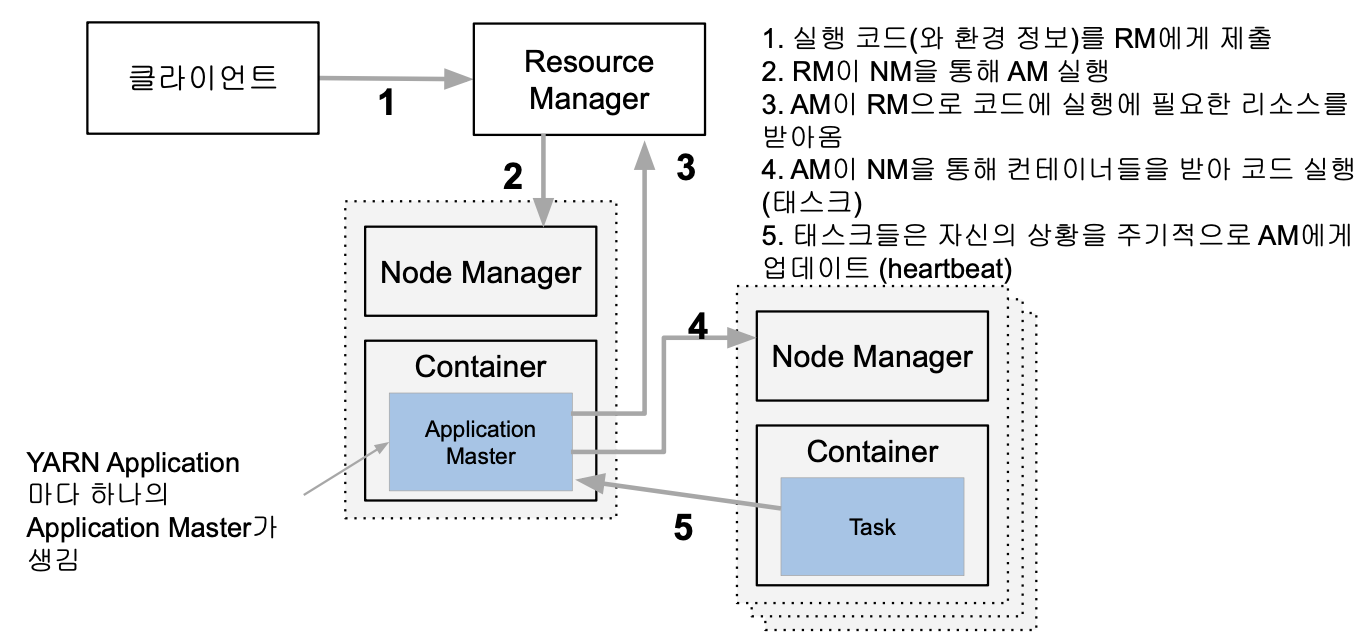
- (클라이언트: MR, Spark 등 ..)
- 실행하려는 코드와 환경 정보를 RM(Resource Manager)에게 넘김
- 실행에 필요한 파일들은 application ID에 해당하는 HDFS 폴더에 미리 복사됨
- RM은 NM(Node Manager)으로부터 컨테이너를 받아 AM(Application Master) 실행
- AM은 프로그램 마다 하나씩 할당되는 프로그램 마스터에 해당
- AM은 입력 데이터 처리에 필요한 리소스를 RM에게 요구
- RM은 data locality를 고려해서 리소스(컨테이너)를 할당
- AM은 할당받은 리소스를 NM을 통해 컨테이너로 론치하고 그 안에서 코드를 실행
- 이 때 실행에 필요한 파일들이 HDFS에서 Container가 있는 서버로 먼저 복사
- 각 태스크는 상황을 주기적으로 AM에게 보고 (heartbeat)
- 태스크가 실패하거나 보고가 오랜 시간 없으면 태스크를 다른 컨테이너로 재실행
하둡 1.0 vs. 하둡 2.0 vs. 하둡 3.0

- 하둡 3.0 은 Yarn 2.0을 사용함
- YARN 프로그램들의 논리적인 그룹(플로우라고 부름)으로 나눠서 자원 관리가 가능. 이를 통해 데이터 수집 프로세스와 데이터 서빙 프로세스를 나눠서 관리 가능 ( 50은 스트리밍, 20은 데이터 서빙 등.. 용도에 맞게 설정 가능하다.)
- 타임라인 서버에서 HBase를 기본 스토리지로 사용 ( 2.1 부터 HBase가 기본임 이전에는 Submarine)
- 파일시스템
- 네임노드의 경우 다수의 스탠바이 네임노드를 지원
- HDFS, S3, Azure Storage 이외에도 Azure Data Lake Storage 등을 지원
'Spark' 카테고리의 다른 글
| [Spark] Spark 내부동작과 클라우드 옵션(Part1. Spark 내부동작) (1) | 2024.02.13 |
|---|---|
| [Spark] Spark 프로그래밍: SQL (3) | 2024.02.13 |
| [Spark] Spark 프로그래밍: DataFrame (2) (0) | 2024.02.12 |
| [Spark] Spark 프로그래밍: DataFrame (1) (1) | 2024.02.11 |
| [Spark] 빅데이터 처리와 Spark 소개(2) (1) | 2024.02.10 |



