2주차 주요내용
1. SQL 특징과 장, 단점
2. SQL DDL과 DML
3. 기본 SQL
4. 고급 SQL

SQL의 특징과 장, 단점
장점)
- 데이터 다루는 직군에서는 SQL만한게 없음
- DDL(Data Definition Language) : create table, drop table, alter table..
- DML(Data Manipulation Language) : select, insert into...
- Hive, Presto(AWS: Athena) SQL 포맷으로 지원해주는 빅데이터 기술이 등장
단점)
- 구조화된 데이터 처리에 최적화되어있음
- Redshift는 nested되어있지 않은 데이터 처리가 특효이다.
SQL 방언이 존재한다 → 비슷하게 생겼지만 standard syntax가 없다. (특히 날짜) - 반정규화, 비정규화 데이터에 대하 처리가 유연하지 않다. (Spark, Hadoop, Hive 등을 대신 사용)
데이터를 다룰때 기억해야할 점

- 현업에서 깨끗한 데이터란 존재하지 않는다.
- 항상 데이터를 의심하자
- 실제 레코드를 몇개 살펴보는 방법밖에 없음(노가다)
- 데이터 일을 한다면 항상 데이터 품질을 의심하고 체크하는 버릇이 필요함
- 중복된 레코드 체크
- 최근 데이터의 존재여부 체크
- PK uniqueness가 지켜지는지 체크
- 값이 비어있는 컬럼이 있는지 체크
- 위의 체크는 unit test형태로 만들어 쉽게 체크할 수 있다.
- 어느 시점이 되면 너무나 많은 테이블이 존재함
- 중요한 테이블이 무엇이고, 메타 정보를 관리하는게 중요
- 테이블에 대해 질문을 하고 싶은데 누구에게 질문을 해야하나?
- 그 시점부터는 Data Discovery 문제들이 생겨난다.
- 이 테이블에 내가 원하고 신뢰할 수 있는 정보가 들어있나?
- 테이블에 대해 질문을 하고 싶은데 누구에게 질문을 해야하나?
SQL DDL과 DML
SQL DDL(Data Definition Language)
Create Table
- PK 속성을 지정해줄 수 있으나 무시됨 → Big Data 웨어하우스에서는 지켜지지 않음 (Redshift, Snowflake, BigQuery)
- CTAS (아주 기초적인 ELT를 구현해주는 문법) Create Table schema_name.table_name As Select → ELT
- DBT의 핵심은 CTAS이다. CTAS의 스테로이드 버전이 DBT이다.
Drop Table
- Drop Table schema_name.table_name;
- 없는 테이블을 지우려고 하는 경우 에러를 낸다.
- DROP TABLE IF EXISTS table_name; vs. DELETE FROM
- DELETE FROM은 조건에 맞는 레코드들을 지운다. (테이블 자체는 존재)
Alter Table
- 새로운 컬럼 추가: ALTER TABLE 테이블이름 ADD COLUMN 필드이름 필드타입;
- 기존 컬럼 이름 변경: ALTER TABLE 테이블이름 RENAME 현재필드이름 to 새 필드이름
- 기존 컬럼 제거: ALTER TABLE 테이블이름 DROP COLUMN 필드이름;
- 테이블 이름 변경: ALTER TABLE 현재테이블이름 RENAME to 새 테이블이름;
SQL DML(Data Manipulation Language)
- Select : 이미 채워져 있는 테이블로부터 결과물을 받아오는 것을 의미함
- 레코드 수정 언어 :
- INSERT INTO : 테이블에 레코드 추가 (copy)
- UPDATE FROM : 테이블 레코드의 필드 값 수정
- DELETE FROM : 테이블에서 레코드를 삭제
- vs. TRUNCATE → DELETE 보다 빠르지만 모든 데이터를 한번에 삭제한다. 조건절이 없다.
기본 SQL
WHERE
In & Like / ILike
- In : Where channel in (’Google’, ‘Youtube’)
- Where channel = ‘Google’ OR channel = ‘Youtube’
- Like & ILike : Like는 UpperCase, LowerCase 구분함 ILike는 구분하지 않음
- Where channel ILike ‘%o%’;
- Where channel Like ‘%o%’; (위와 결과값이 서로 다르다.)
String Functions
- LEFT(str, N) : str의 왼쪽에서부터 N개의 문자를 추출한다.
- REPLACE(str, exp1, exp2) : str에서 exp1을 찾아 exp2로 대체한다.
- UPPER(str) : 대문자 변환
- LOWER(str) : 소문자 변환
- LEN(str) : 길이수 반환 (=LENGTH)
- LPAD, RPAD(str, N, padstr) : 문자열 ‘str’의 왼쪽을 문자 padstr로 채워 전체길이 N이 되도록 함
- SUBSTRING(str, start, N) : 특정 위치에서 시작하여 길이 ‘N’ 만큼의 부분 문자열을 추출한다. (=SUBSTR)
Type Cast and Conversion
Date Conversion
- convert_timezone : 다른 시간대로 변환한다.
- Date : 날짜 값을 나타내는 데이터 타입
- Date_Trunc : 날짜를 특정 단위로 절삭하여 반환한다.
- DateDiff, DateAdd : 두 날짜 사이의 차이를 계산하는 함수, 날짜나 시간에 일정한 값을 더할 때
Type Casting and Conversion
- cast 또는 :: 연산자를 사용해서 캐스팅한다.
- category::int or cast(category as int)
- to_char, to_timestamp : 날짜형은 관계형 DB마다 서로다름
- Declarative language vs. Procedure language : SQL은 선언형 언어이다.
NULL
- 값이 존재하지 않음을 의미함 → 0이나 str 형태와는 다름을 인지하자
- 사칙연산에 NULL로 나누면? → 모든 값이 null로 나온다.
- Aggregation함수(count) 에서는 예외임
- NULL 값을 다른 값으로 변환하고 싶으면 COALESCE를 사용한다. 또는, NULLIF 사용한다.
JOIN
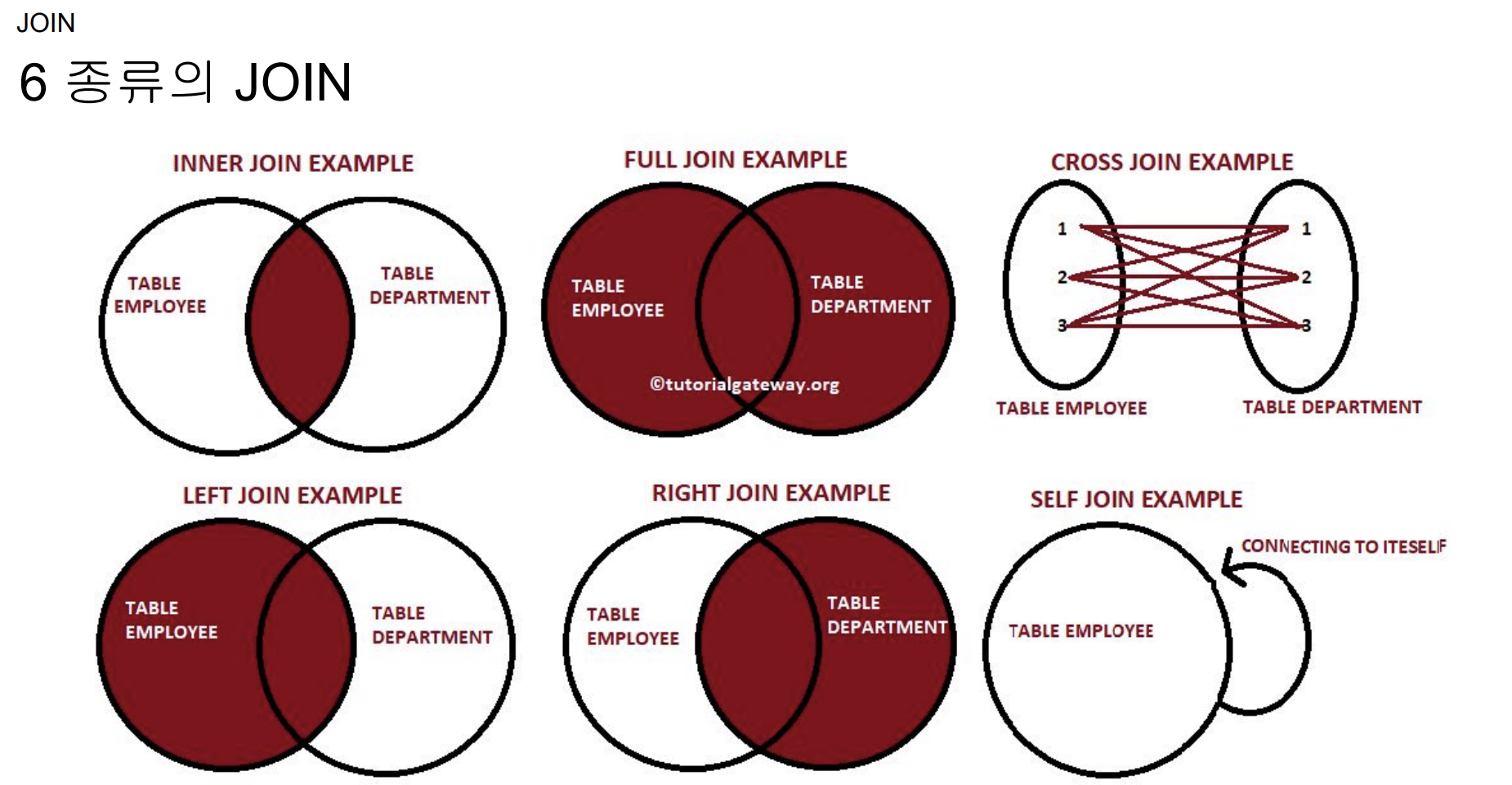
- 중복 레코드가 없고 PK의 uniqueness가 보장됨을 체크한다. → 아주 중요함!!
- 95% 이상의 join은 (INNER)Join, Left Join
- Inner Join은 매칭되는 경우에만
- Left Join 은 왼쪽만 살아남음
- Full Join 둘다 살아남음
- Cross Join 모든 컬럼에 대해 모든 경우의수를 가지는 join
고급 SQL
UNION, EXCEPT
- UNION (합집합): 여러개의 테이블들이나 SELECT 결과를 하나의 결과로 합쳐줌
- UNION vs. UNION ALL : UNION은 중복을 제거
- EXCEPT (MINUS)
- 하나의 SELECT 결과에서 다른 SELECT 결과를 빼주는 것이 가능
- INTERSECT (교집합)
- 여러 개의 SELECT문에서 같은 레코드들만 찾아줌
COALESCE, NULLIF
- COALESCE(Expression1, Expression2, …): 첫번째 Expression부터 값이 NULL이 아닌 것이 나오면 그 값을 리턴하고 모두 NULL이면 NULL을 리턴한다.
- NULL값을 다른 값으로 바꾸고 싶을 때 사용한다.
- NULLIF(Expression1, Expression2): Expression1과 Expression2의 값이 같으면 NULL을 리턴한다
DELETE FROM vs. TRUNCATE
- DELETE FROM table_name (not DELETE * FROM)
- 테이블에서 모든 레코드를 삭제
- vs. DROP TABLE table_name
- WHERE 사용해 특정 레코드만 삭제 가능: DELETE FROM raw_data.user_session_channel WHERE channel = ‘Google’
- TRUNCATE table_name도 테이블에서 모든 레코드를 삭제
- DELETE FROM은 속도가 느림
- TRUNCATE이 전체 테이블의 내용 삭제시에는 여러모로 유리하지만 두가지 단점이 존재
- TRUNCATE는 WHERE을 지원하지 않음
- TRUNCATE는 Transaction을 지원하지 않음
WINDOW
- Syntax: function(expression) OVER ( [ PARTITION BY expression] [ ORDER BY expression ] )
- Useful functions:
- ROW_NUMBER, FIRST_VALUE, LAST_VALUE
- Math functions: AVG, SUM, COUNT, MAX, MIN, MEDIAN, NTH_VALUE
SUB Query (CTE)
- SELECT를 하기 전에 임시 테이블을 만들어서 사용하는 것이 가능
- 임시 테이블을 별도의 CREATE TABLE로 생성하는 것이 아니라 SELECT 문의 앞단에서 하나의 SQL 문으로 생성
- 문법은 아래와 같음 (channel이라는 임시 테이블을 생성)
WITH channel AS (
select DISTINCT channel from raw_data.user_session_channel
),
temp AS (select ...),
...
SELECT *
FROM channel c
JOIN temp t ON c.userId = t.userId
2주차 후기
SQL 내용은 선수지식이 부족하지 않아서 이번주차 강의를 듣는데 큰 어려움이없었다.
WINDOW, Sub Query등 고급 SQL 문법을 알 수 있었다.
데이터 품질에 대한 고민을 좀 더 해야겠다.
'Airflow' 카테고리의 다른 글
| [데이터엔지니어] 실리콘 밸리에서 날아온 엔지니어링 스타터 키트 Week6 (0) | 2023.10.11 |
|---|---|
| [데이터엔지니어] 실리콘 밸리에서 날아온 엔지니어링 스타터 키트 Week5 (2) | 2023.10.10 |
| [데이터엔지니어] 실리콘 밸리에서 날아온 엔지니어링 스타터 키트 Week4 (1) | 2023.10.09 |
| [데이터엔지니어] 실리콘 밸리에서 날아온 엔지니어링 스타터 키트 Week3 (0) | 2023.09.05 |
| [데이터엔지니어] 실리콘 밸리에서 날아온 엔지니어링 스타터 키트 Week1 (0) | 2023.08.21 |



