6주차 주요내용
- OLTP 테이블 복사하기
- Backfill 실행하기
- Summary 테이블 만들기 (ELT)

MySQL(OLTP) 테이블 복사하기

- 서비스 운영을 위한 데이터를 MySQL에 적재해놓는다.
- OLTP(Online Transaction Process) : 서비스를 운영하는데 필요한 최소한의 정보등록
→ OLAP(Online Analytical Process) : 데이터 분석과 데이터 프로세싱을 위한 DB구축
MySQL .nps 데이터를 Redshift nps 데이터에 적재하는 두가지 방법

- MySQL에서 레코드 하나씩 읽어온 다음에 INSERT 로 루프돌면서 적재시키기
- upsert가 지원이 되지 않고 INSERT/UPDATE 과정을 두번 거쳐야하기 때문에 오래걸림
- COPY를 통해 UPSERT를 구현 할 수 있다.
- COPY 커맨드를 안쓰고 INSERT 할때는 바로 Redshift에 적재하면 되었는데 bulk update를 하기 위해서는 적재된 정보를 먼저 S3에서 올려두고 사용해야한다.
- S3는 쉽게 생각해서 하드디스크랑 동일함, 이를 버킷이라고 지정해놓음
AWS 관련 권한 설정
- Airflow DAG에서 S3 접근(쓰기 권한)
- IAM USER을 만들고 S3 버킷에 대한 읽기/쓰기 권한 설정하고 access key 와 secret key사용
- Redshift가 S3 접근(읽기 권한)
- Redshift에 S3를 접근할 수 잇는 역할을 만들고 이를 Redshift에 지정
- IAM 을 사용해서 S3 계정이 털리더라도, S3 해커들이 접근 못하도록 방지한다.
MySQL Connection 설정시 유의사항
- 아래 명령을 Airflow Scheduler Docker Container에 root유저로 로그인하여 실행
docker exec --user root -it **0017662673c3** sh
(airflow) sudo apt-get update
sudo apt-get install -y default-libmysqlclient-dev
sudo apt-get install -y gcc
sudo pip3 install mysqlclient
- 이 부분은 실행하는 시점에 따라 다른 문제들이 존재할 수 있음
- 위의 명령은 No module names ‘MySQLdb’ 에러를 해결하기 위함임
- 이상적으로는 docker-compose.yaml 파일을 수정해서 위의 모듈들을 설치해주는 것이 좋음
- 만약 Airflow image가 MySQL의 dependency와 연관이 있는 이미지를 사용한다면, 더 쉬워진다.
MySQL의 테이블 리뷰 (OLTP, Production Database)
CREATE TABLE prod.nps (
id INT NOT NULL AUTO_INCREMENT primary,
created_at timestamp,
score smallint
);
Redshift(OLAP, Data Warehouse)에 해당 테이블 생성
CREATE TABLE MyName.nps(
id INT NOT NULL primary key,
created_at timestamp,
score smallint
);이미 테이블은 이미 MySQL쪽에 만들어져 있고 레코드들이 존재하며, Redshift로 복사하는 것이 실습 과정
- 전제: Append Only 테이블이라는 전제가 있음 (삭제/수정 불가)
SqlToS3Operator
- MySQL SQL 결과 -> S3
- (s3://grepp-data-engineering/{본인ID}-nps)
- s3://s3_bucket/s3_key
S3ToRedshiftOperator
- S3 -> Redshift 테이블
- (s3://grepp-data-engineering/{본인ID}-nps) -> Redshift (본인스키마.nps)
- COPY command is used
→ 이미 Airflow에서 존재하는 S3Operator 을 가지고와서 사용하면됨
mysql_to_s3_nps = SqlToS3Operator(
task_id = 'mysql_to_s3_nps',
query = "SELECT * FROM prod.nps",
s3_bucket = s3_bucket,
s3_key = s3_key,
sql_conn_id = "mysql_conn_id",
aws_conn_id = "aws_conn_id",
verify = False,
replace = True,
pd_kwargs={"index": False, "header": False}, #기본은 csv형태로 저장, json등으로 변환하고 싶으면 이부분 변경
dag = dag
)
s3_to_redshift_nps = S3ToRedshiftOperator(
task_id = 's3_to_redshift_nps',
s3_bucket = s3_bucket,
s3_key = s3_key,
schema = schema,
table = table,
copy_options=['csv'],
method = 'REPLACE',
redshift_conn_id = "redshift_dev_db",
aws_conn_id = "aws_conn_id",
dag = dag
)
- query 라는 파라미터를 실행하고 싶은데, 그 대상이 sql_conn_id = ‘mysql_conn_id’으로 지정해놓음 (데이터 소스)
- 그걸 바탕으로 이제 S3에 저장해야 하는데, 어떤 S3인지 인증을 하기 위해 aws_conn_id 를 정의한다.
- replace=True 지정해놓으면 매번 full-refresh를 한다. 만약, 이미 정보가 존재하면 이 작업은 실패한다.
- method가 REPLACE 로 되어있다면 full-refresh 로 됨.
- upsert 하고 싶으면 id 기준으로 upsert라고 적으면 됨
정리하자면…
- query를 prod.nps 의 모든 레코드들을 읽어오고, 읽어다가 s3_bucket에 s3_key로 지정된 path에다가 파일을 하나 만드는 것이다.
- S3 에 저장된 3가지의 parameter(bucket, key, aws_conn_id)를 통해 정보를 가져와 ‘redshift_conn_id’로 지정된 schema 밑의 테이블로 .csv 형태로 업데이트(저장)하라
MySQL 테이블의 Incremental Update(1)
- MySQL/PostgreSQL 테이블이라면(좋은 관계형 DB table 디자인을 위해서) 다음을 세가지를 만족해야함
- created (timestamp): 모든 레코드들은 생성된 시간을 기록하고 있어야 한다. (Optional)
- modified (timestamp) : 모든 레코드들은 수정된 시간을 기록하고 있어야 한다.
- deleted (boolean): 레코드를 삭제하지 않고 deleted를 True로 설정
- 어떤 레코드를 삭제할 때, 그냥 날려버리지 않고 deleted 필드를 True로 설정한다.
- Incremental update를 할 때는 그냥 modified 값만 보면 된다. (가령, 하루에 한번 돌아가는 daily dag 라면 modified 에서 전날 값만 확인하면 된다.)
MySQL 테이블의 Incremental Update 방식 (2)
- Daily Update이고 테이블의 이름이 A이고 MySQL에서 읽어온다면
- ROW_NUMBER로 직접 구현하는 경우
- 먼저 Redshift의 A 테이블의 내용을 temp_A로 복사
- MySQL의 A 테이블의 레코드 중 modified의 날짜가 지난 일(execution_date)에 해당하는 모든 레코드를 읽어다가 temp_A로 복사
- 아래는 MySQL에 보내는 쿼리. 결과를 파일로 저장한 후 S3로 업로드하고 COPY 수행
- SELECT * FROM A WHERE DATE(modified) = DATE(execution_date)
- temp_A의 레코드들을 primary key를 기준으로 파티션한 다음에 modified 값을 기준으로 DESC 정렬해서, 일련번호가 1인 것들만 다시 A로 복사
MySQL 테이블의 Incremental Update 방식 (3)
- Daily Update이고 테이블의 이름이 A이고 MySQL에서 읽어온다면
- SqlToS3Operator로 구현하는 경우
- query 파라미터로 아래를 지정 (아까와는 다르게, where 조건을 붙여준다.)
- SELECT * FROM A WHERE DATE(modified) = DATE(execution_date)
- query 파라미터로 아래를 지정 (아까와는 다르게, where 조건을 붙여준다.)
- S3ToRedshiftOperator로 구현하는 경우
- method 파라미터로 “UPSERT”를 지정
- upsert_keys 파라미터로 Primary key를 지정
- 앞서 nps 테이블이라면 “id” 필드를 사용
sql = "SELECT * FROM prod.nps WHERE DATE(created_at) = DATE('{{ execution_date }}')”
- {{text}} : jinja 템플릿, flask에서 사용하는 값이 치환되는 방식이다.
Backfill 실행하기
Backfill을 커맨드라인에서 실행하는 방법(daily dag라는 전제)
airflow dags **backfill** dag_id **-s** 2018-07-01 **-e** 2018-08-01
- 다음이 준비되어 있어야함:
- catchUp이 True로 설정되어 있음 (기본적으로 incremental이라면 True로 설정하는게 기본임)
- execution_date을 사용해서 Incremental update가 구현되어 있음
- start_date부터 시작하지만 end_date은 포함하지 않음
- 실행순서는 날짜/시간순은 아니고 랜덤. 만일 날짜순으로 하고 싶다면
- DAG default_args의 depends_on_past를 True로 설정 default_args = { 'depends_on_past': True, …
How to Make Your DAG Backfill ready(1)
- 먼저 모든 DAG가 backfill을 필요로 하지는 않음
- Full Refresh를 한다면 backfill은 의미가 없음
- 여기서 backfill은 일별 혹은 시간별로 업데이트하는 경우를 의미함
- 마지막 업데이트 시간 기준 backfill을 하는 경우라면 (Data Warehouse 테이블에 기록된 시간 기준) 이런 경우에도 execution_date을 이용한 backfill은 필요하지 않음
- 데이터의 크기가 굉장히 커지면 backfill 기능을 구현해 두는 것이 필수
- airflow가 큰 도움이 됨
- 하지만 데이터 소스의 도움 없이는 불가능
How to Make Your DAG Backfill ready(2)
- 어떻게 backfill로 구현할 것인가
- 제일 중요한 것은 데이터 소스가 backfill 방식을 지원해야함
- “execution_date”을 사용해서 업데이트할 데이터 결정
- “catchup” 필드를 True로 설정
- start_date/end_date을 backfill하려는 날짜로 설정
- 다음으로 중요한 것은 DAG 구현이 execution_date을 고려해야 하는 것이고 idempotent 해야함
Summary Table 구현
- MAU 요약 테이블을 만들어보자 (이부분을 dbt로 구현하는 회사도 많음)
sql = f"""DROP TABLE IF EXISTS {schema}.temp_{table};CREATE TABLE {schema}.temp_{table} AS """
sql += select_sql
cur.execute(sql)
cur.execute(f"""SELECT COUNT(1) FROM {schema}.temp_{table}""")
count = cur.fetchone()[0]
if count == 0:
raise ValueError(f"{schema}.{table} didn't have any record")
- 바로 CTAS를 하는게 아니라 ‘temp_’ 를 붙인 임시테이블에다가 해놓고 하나라도 만들어진게 확인되면 그때 rename하는 방식으로 진행함
- 만약 반환되는 값이 0이면 Error 발생하는 식으로 진행됨
- 하나라도 있으면 원본 테이블을 삭제하고 rename
→ 이런 작업을 자동화 해주는 것이 dbt 이다.
JSON형태로 기록이 되는 nps_summary.py
{
'table': 'nps_summary',
'schema': 'MyName',
'main_sql': """
SELECT LEFT(created_at, 10) AS date,
ROUND(SUM(CASE
WHEN score >= 9 THEN 1
WHEN score <= 6 THEN -1 END)::float*100/COUNT(1), 2)
FROM MyName.nps
GROUP BY 1
ORDER BY 1;""",
'input_check':
[
{
'sql': 'SELECT COUNT(1) FROM MyName.nps',
'count': 150000
},
],
'output_check':
[
{
'sql': 'SELECT COUNT(1) FROM {schema}.temp_{table}',
'count': 12
}
],
}- 이런 형태로 테스트를 실행할 수 있다.
- .config 파일 아래에다가 테스트할 파일을 놓을 수 있다.
- 위와 같은 dbt-like 정보 파일들을 여러개 배치할 수 있다.
- 내가 만들고 싶은 summary table 별로 파일을 만들어두기 (JSON 형태로)
- CTAS 구성하고 + @로 input/output 체크를 붙여놓을 수 있다.
dag폴더 밑에 config폴더를 뒤져본다, config 파일밑에 있는 모든 파일들을 로딩해라
그중에서도 ‘tables_load’ 에 이름이 저장되어있는것만 빌드해라


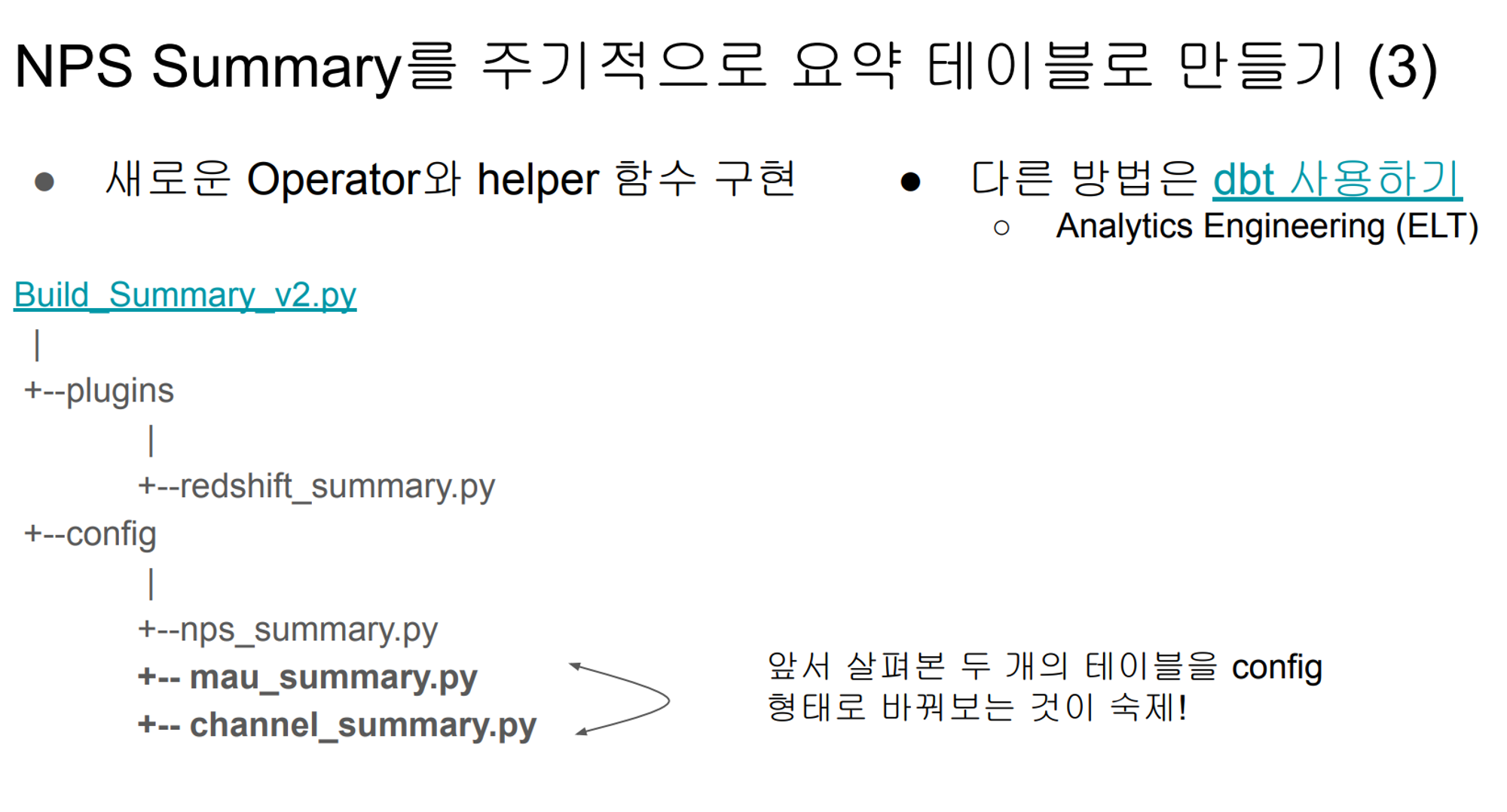
요약하자면…
- build_summary_v2 에서 plugins의 redshift_summary.py 의 기능을 쓰게되고
- config 폴더 밑에 내가 필요한 summary table을 가져와서 사용한다.
6주차 후기
데이터를 가져오고 'dbt' 에 있는 부가 기능을 구성하는 방법을 알게되었다.
가져온 데이터로 nps 라는 지표를 만들어서 고객의 만족도를 조사해서 의사결정에 사용될 수 있다는걸 배웠다.
어느새 마지막 주차를 앞두고 있는데.. 많은 걸 배워갈 수 있는 시간이라서 시원섭섭하다는 생각을 하게 된다.
'Airflow' 카테고리의 다른 글
| [Apache Airflow 기반의 데이터 파이프라인] Airflow 콘텍스트를 사용하여 태스크 템플릿 작성하기 (0) | 2024.02.17 |
|---|---|
| [데이터엔지니어] 실리콘 밸리에서 날아온 엔지니어링 스타터 키트 Week7 (0) | 2023.10.12 |
| [데이터엔지니어] 실리콘 밸리에서 날아온 엔지니어링 스타터 키트 Week5 (2) | 2023.10.10 |
| [데이터엔지니어] 실리콘 밸리에서 날아온 엔지니어링 스타터 키트 Week4 (1) | 2023.10.09 |
| [데이터엔지니어] 실리콘 밸리에서 날아온 엔지니어링 스타터 키트 Week3 (0) | 2023.09.05 |



