

- 주요 Redis 특징
- Redis 사용 분야
- Cache
- Session Store
- Distributed Lock
- Rate Limiter
- LeaderBoard
- Queue
주요 Redis 특징
- Redis(Remote Directory System) 는 키밸류 DB이면서 대표적인 In Memory 기반의 데이터 처리 및 저장기술을 제공한다. 다른 NoSQL 제품에 비해 상대적으로 빠른 R/W 을 지원한다.
- 파티셔닝을 통해 동적인 스케일 아웃(Scale Out)인 수평 확장이 가능하다.
- Expiration 기능으로 일정 시간이 지날 때 메모리 상의 데이터를 자동 삭제할 수 있다.
- Master/Slave Replication 기능을 통해 데이터의 분산, 복제 기능을 제공하며 Query Off Loading 기능을 통해 Master은 R/W 를 수행하고 Slave는 Read만 수행할 수 있다.

Redis server, client (Standalone mode)

redis의 기본 포트는 6379로 설정되어있다. 또한, cli에서 info 입력을 통해 Server / Client의 정보를 읽어올 수 있다.
Redis 사용분야
Cache (Look aside, Write back ... ), Distributed Cache
DB에 가져가지 않고 Redis에 1차적으로 저장한다. 다양한 타입의 다양한 정보를 필요에 따라 저장할 수 있다.
#Look aside Cache
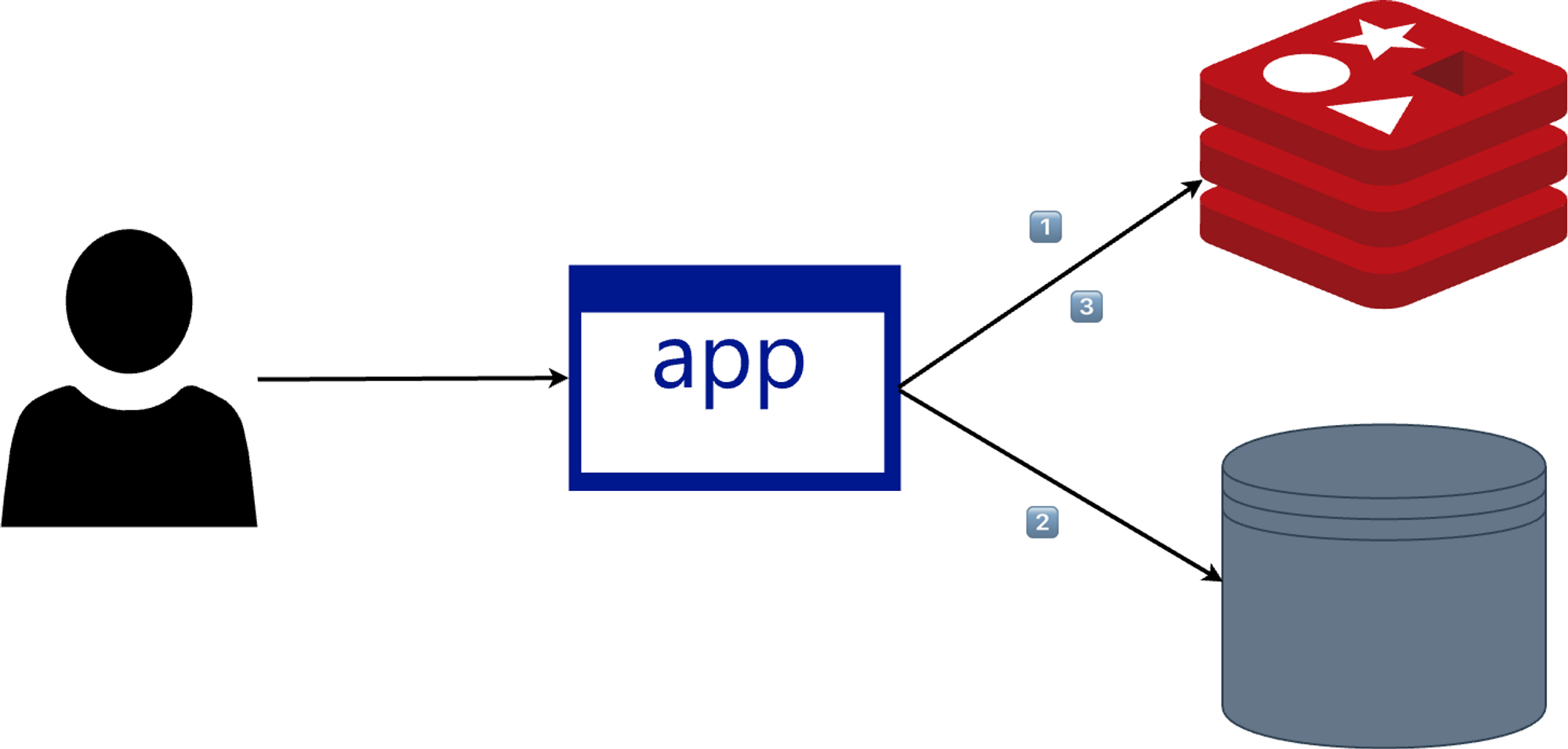
- 웹서버는 데이터가 존재하는지 캐시를 먼저 확인한다.
- 캐시에 데이터가 있으면 캐시에서 가져온다
- 만약 캐시에 데이터가 없다면 DB에서 읽어온다.
- DB에서 읽어온 데이터를 Cache에 다시 저장한다.
반복적인 호출이 많은 경우 적합한 전략이다.
#Write Back Cache

- 웹서버는 모든 데이터를 캐시에만 저장한다. (캐시가 큐의 역할을 한다.)
- 캐시에 특정 시간동안의 데이터가 저장된다.
- 캐시에 있는 데이터를 DB에 저장한다.
- DB에 저장된 데이터를 삭제한다.
데이터 적합성이 높고 DB요청 수를 줄일 수 있지만 캐시에 장애가 발생할 경우 데이터가 유실되며 사용하지 않는 정보까지 캐시에 저장한다.
이외에도 cache 전략은 read through, write through, write around 가 있다.
https://tech.socarcorp.kr/dev/2023/06/27/handling-authentication-token-traffic-01.html
#Distributed Cache
- 데이터가 많다면, 하나의 캐시 서버가 아니라 여러 캐시 서버를 구성할 수 있다.
ex) Redis w/ Range, Redis w/ PreShard, Redis w/ Consistent Hashing



<Consistent Hashing>
- Consistent Hashing 을 통해서 key 를 분할
- 없어져도 다시 만들 수 있는 Cache 형태에 적합
- <Consistent Hashing 의 단점>
- HashRing 을 균등하게 구성하더라도 부하는 균등하게 몰리지 않는다.
- Hot Key등
- 필요한 개수보다 더 많은 노드가 필요한 경우가 종종 발생.
Session Store
Session 을 개별서버나, 클러스터링이 아니라. 외부 스토리지(Redis)에 저장

웹 개발할 때 redis를 세션저장소로 사용할 수 있는 구성이다.
주로 스프링으로 개발할 때 관련 의존성을 빌드하면 레디스를 간편하게 사용할 수 있도록 지원해준다.
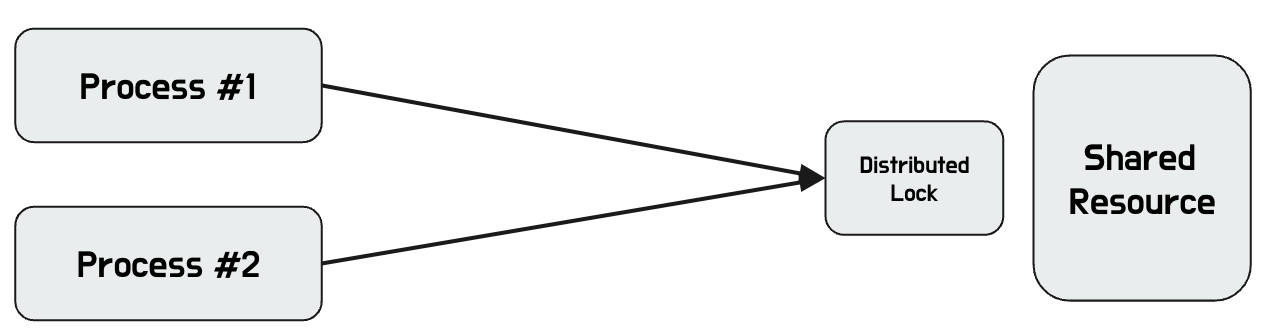
Distributed Lock ( Lettuce - spinlock, Redisson - pubsub)
서버간 동기화된 처리가 필요하고, 여러 서버에 공통된 락을 적용하기 위해 redis를 이용하여 분산락을 이용한다.
db등 공통된 데이터 저장소를 이용해 자원이 사용중인지 확인하기 때문에 전체 서버에 동기화된 처리가 가능하다.
- 분산 락으로 동작
- 낙관적 락(Optimistic Lock) (=어플리케이션이 제공하는 락) 으로 동작
- Key가 존재하면 대기하는 형태 (바로 실패로 구성할지, Spinlock 형태로 동작할지의 고민 필요)
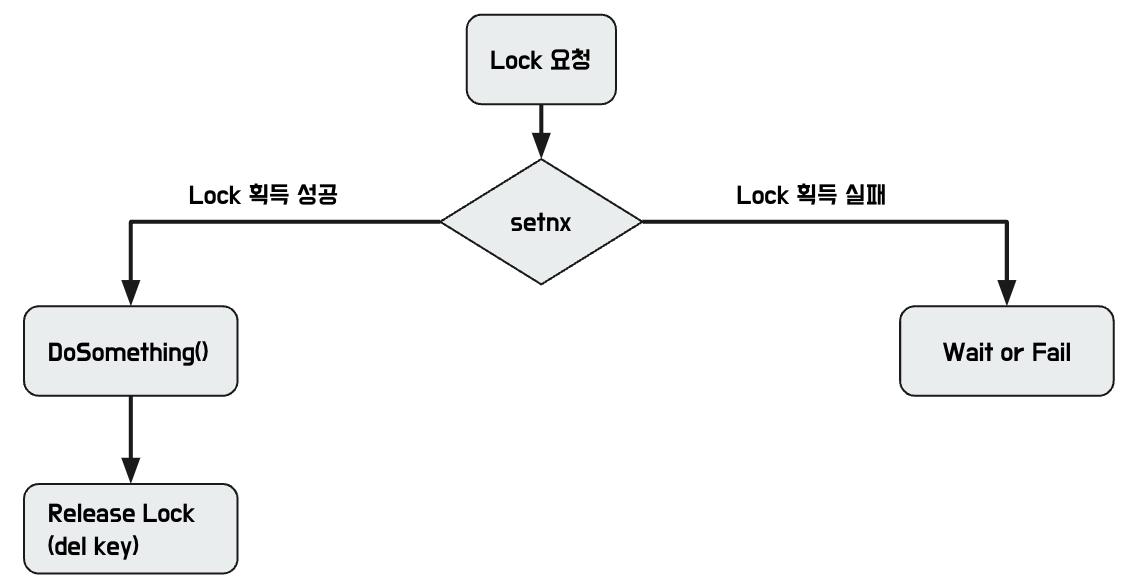
- setnx 의 특성을 이용하여, 하나만 Key 생성이 가능.
- setnx로 Lock을 얻을 때는 해당 프로세스에 문제가 발생할 수 있으므로 ttl(time to live)을 꼭 설정한다.(충분한 시간으로)
- Lock 실패시에는 spin lock형태로 계속 대기하거나 해당 작업 자체를 실패시키고 다시 retry 하는 전략을 취할 수 있다.
- Lock 획득 시간이 길어지면, ttl로 Lock이 풀려서 중복 작업이 발생할 수 있다.
ex) Lettuce : spinlock 으로 구현되어있고 lock의 타임아웃 설정이 되어있지 않음 (Redis에 과부화)
Redisson : Lock에 타임아웃이 구현되어 있다. 스핀락을 사용하지 않고 pubsub 기능을 이용, Lua 스크립트 사용한다.
https://redis.io/docs/manual/patterns/distributed-locks/
https://hyperconnect.github.io/2019/11/15/redis-distributed-lock-1.html
https://soyeon207.github.io/db/2021/08/29/distributed-lock.html
Rate Limiter
서비스를 운영하면서 가용성을 유지하기 위해 클라이언트의 과도한 사용에 대해 보호해야 한다. 이러한 방안으로 Rate Limit 알고리즘을 적용할 수 있다.
- 잦은 업데이트가 필요한 경우, 저장소로 사용되는 케이스
- 일종의 Write back 형태 or 전용 저장소로 동작한다.
- Rate Limiter 이외에 View Count 등을 저장할때도 사용된다.
- 5가지의 Rate Limit 알고리즘 종류가 있다.
- Leaky Bucket: 네트워크로의 데이터 주입 속도의 상한을 정하고, 트래픽 체증을 일정하게 유지한다.
- Token Bucket: 평균 유입 속도를 제한하고 처리 패킷 손실없이 특정 수준의 버스트 요청 허용가능
- Fixed Window Counter: 정해진 시간 단위로 window가 만들어지고 요청 건수가 기록되어 해당 window의 요청 건수가 정해진 건수보다 크면 해당 요청은 처리가 거부된다. (구현은 쉽지만, 기간 경계의 트래픽 편향 문제가 생김)
- Sliding Window Log: Fixed Window Counter 의 단점인 기간 경계의 편향에 대응하기 위한 알고리즘이다. window의 요청건에 대한 로그를 관리해야하기 때문에 구현과 메모리 비용이 높은 단점이 있다.
- Sliding Window Counter: Fixed window counter, Sliding window log의 로그 보관 비용 등의 문제점을 보완할 수 있는 알고리즘이다.
https://www.mimul.com/blog/about-rate-limit-algorithm/
LeaderBoard (Sorted Set - zset)
Sorted Set(zset)이 score로 저장할 수 있으므로 이를 응용하여 리더보드로 이용가능, DBMS로 할 수 있는 부분이지만 속도가 빠르다.
member 추가하기
$ ZADD <key> <score> <member>
score 작은 순서로 순위 조회하기 (1순위부터 보고 싶으면 0으로 시작)
$ ZADD <key> <시작> <끝> REVscore 큰 순서로 순위 조회하려면 후위에 REV를 붙인다.

sorted set 이외로도 Redis에서 제공하는 데이터 타입에 대한 이야기는 다음에 포스팅하겠다.
'Redis' 카테고리의 다른 글
| [完][OSSCA Redis] Redis 오픈소스 컨트리뷰션 (0) | 2024.01.31 |
|---|---|
| [OSSCA Redis / 빅데이터 저장 및 분석을 위한 NoSQL & Redis] Part3 (0) | 2023.11.01 |
| [OSSCA Redis / 빅데이터 저장 및 분석을 위한 NoSQL & Redis] Part1 (1) | 2023.10.24 |
| [OSSCA Redis] Redis 오픈소스 컨트리뷰션 Week3 (1) | 2023.10.23 |
| [OSSCA Redis] Redis 오픈소스 컨트리뷰션 Week1, 2 (0) | 2023.10.15 |



